Kinship and language: a computer-aided study of social deixis
in conversation. R000 23 3311
Summary of Aims
The proposed research has
both descriptive and theoretical objectives (unchanged from
original application):
1) Theoretical.
It is hoped to develop a method of studying kinship employing
theory and techniques deriving from pragmatics and conversation
analysis, instead of more conventional anthropological methods.
It will then be possible by examining Dr Zeitlyn's Mambila data
to demonstrate the power of analysing kin terms as part of a set
which also includes proper names, pronouns and titles. This will
constitute a significant re-casting of the anthropological theory
of kinship.
The validity of this approach to the study of kinship will be
further tested by the computer-assisted study of linguistic
corpora from a range of other societies to show that the method
is capable of far wider application. It will also demonstrate the
benefits of this style of analysis to a wider audience than may
be expected to read studies of a single African group.
2) Descriptive.
The descriptive objective of the project is to undertake an
analysis of Mambila kinship, both demographic and linguistic.
Much relevant information has already been collected and is
currently recorded in unpublished fieldnotes. This data will now
be collated into a form which may be checked and completed in the
course of further fieldwork. The fieldwork will also produce new
data for analysis in accordance with of the theoretical position
outlined below.
A wide range of data, particularly in the form of transcripts of
naturally occurring conversation, will be made available for
other researchers.
3. Significant Achievements
1 The establishment
of a systematic cross-cultural approach to the use of social
deictic expressions in naturally occurring conversation
2 The production and archiving of high quality natural language
data from an 'obscure' African language providing data for hard
tests of 'universal' theories developed only on well documented
European languages. Such languages cannot be used legitimately as
the sole basis for universal claims.
3 The development and testing of a coding scheme allowing
comparisons to be made between strategies of person reference
from different languages and cultures
4 The demonstration that anthropological research on kinship
terms can be clearly related to empirical evidence of language in
use.
5 The development of systematic tests for identifying different
speakers and transisitions between topics on the basis of
analysis of transcript alone. Although still under developement
this stands to have important implications for machine
understanding of texts.
4 Dissemination
Publications that have already resulted from the project are
listed below, others are in preparation.
- Further papers in draft (at point of submission to major
journals)
-
- Introducing Mambila Social Deixis
- Summing Up Kin talk
Asking about people, not about kin terms: an essay on method
and interpretation
The main data has already been archived as part of the Child
Language Interchange (CHILDES) project and is being distributed
by them (with full acknowledgement of the ESRC) both online and
on CD.
It is planned to present some of the results at major
international conferences over the next two years as the final
results are fully tested and completed.
Some of the theoretical background to the project has been used
in briefings given to Nokia Mobile Phones, UK.
5 Nominated Publications
- Wilson, A.J. & D. Zeitlyn. 1995. The Distribution of
Person Referring Terms in Natural
- Conversation. Research on Language and Social
Interaction 28(1), 61-92.
- Zeitlyn, D. 1993. Reconstructing Kinship or the pragmatics
of kin talk. Man 28(2),
- 199-224.
7 Major Difficulties
The systematic coding of
the Mambila data took somewhat longer than anticipated. We
decided to concentrate on producing less very-high-quality
transcript rather than more lower-quality data, and succeeded in
coding, and double checking with the original speakers a
conversation containing some 1302 utterances which is sufficient
to allow statistically significance results to be achieved. In
the light of the current ESRC funded research of Dr Bruce Connell
no dictionary or lexicon was produced as had been originally
intended but the source data is being collaboratively worked on
by Zeitlyn and Connell as part of Connell's continuing research
on the Mambila language.
8 Other Issues and Unexpected Outcomes
In the course of
developing the coding scheme we realised how the theory could be
further expanded and tested by coding extra data from which some
of the social context had been removed. If this were successful
it would both vindicate the theory and point to ways in which the
methods could have application to the automatic processing of
speech. Sadly the ESRC declined to fund the extra work. This led
Mr Wilson to leave to the project to work as a marketing
consultant. He was the research assistant who could have
undertaken this work speedily and efficiently without further
(expensive) training had his contract been extended. Zeitlyn has
concentrated in finishing the main project but hopes, if further
funding can be obtained to pursue this extension of the work.
{{Page X}}
Summary of Research Results
The aim of this project was
to study the usage of person referring expressions in corpora of
naturally occurring language in order to provide substantive
evidence for the theoretical constructions about the meaning of
kinship terms that have characterised a century of
anthropological theorising. The methodological inspiration for
our approach may be found in ethnomethodology and in particular
in the fields of conversational analysis and pragmatics.
To take an example from home: speakers of English 'know' that
children use kin terms to address their parents and receive
names. Like other conversational maxims this may not always be
the case but variants from the norm will be marked. For example,
a child may shift pattern in imitation of a political act on the
part of an elder sibling. The irony is that the intention to be
like one's big brother commits one to the political implications
of his acts. One of the strengths of anthropology is its
sensitive analysis of such unintended consequences.
By coding transcripts of 'actual' (unprompted) conversation we
were able to study systematically the choices made by speakers
between the many different possibilities open to them: to refer
to X as e.g. Cousin, Cousin Jean, Jean, Shorty etc. etc. The
coding scheme allows us to correlate the choice of term with the
relationship between the speakers (and the referent) as well as
the sort of speech event occuring.
The application of this approach to English and Mambila language
data has permitted some systematic comparative analyses (which
are still underway) and has generated a significant data set for
the use of other researchers.
{{Page X}}
Full Report of Research Activities and
Results
Background This project concerns the distribution of kin terms
and other referring expressions as they occur in natural
conversation. Some cross cultural comparisons are being made
between data drawn from American sources and from my research
with the Mambila in Cameroon. Some of the successes and
difficulties that have been encountered are outlined below.
Objectives
The original proposal included the following
objectives, which were satisfactorily achieved.
1) Theoretical.
It is hoped to develop a method of studying kinship employing
theory and techniques deriving from pragmatics and conversation
analysis, instead of more conventional anthropological methods.
It will then be possible by examining Dr Zeitlyn's Mambila data
to demonstrate the power of analysing kin terms as part of a
set which also includes proper names, pronouns and titles. This
will constitute a significant re-casting of the anthropological
theory of kinship.
The validity of this approach to the study of kinship will be
further tested by the computer-assisted study of linguistic
corpora from a range of other societies to show that the method
is capable of far wider application. It will also demonstrate
the benefits of this style of analysis to a wider audience than
may be expected to read studies of a single African group.
2) Descriptive.
The descriptive objective of the project is to undertake an
analysis of Mambila kinship, both demographic and linguistic.
Much relevant information has already been collected and is
currently recorded in unpublished fieldnotes. This data will
now be collated into a form which may be checked and completed
in the course of further fieldwork. The fieldwork will also
produce new data for analysis in accordance with of the
theoretical position developed as part of the project.
A wide range of data, particularly in the form of transcripts
of naturally occurring conversation, will be made available for
other researchers.
Methods
The transcription procedures deserve some
mention. Soon after making the recording I went through it with
an informant in the village in Cameroon. At this stage as well as
making some contextual notes we made a second recording - the
informant repeated each utterance into a second tape recorder,
speaking slowly and clearly. To do this he used both his
understanding as a native speaker and the fact that he was an
actor in the conversation to understand parts of the recording
that were (and remain) extremely indistinct to my foreign ears.
In the course of making this second recording he explained
various idioms and vocabulary items that were new to me. I
transcribed the second recording in the UK and then returned to.
I checked this transcript against the original recording since
the slow repetitions often corrected infelicities of grammar or
removed elisions resulting from fast speech. During a subsequent
fieldtrip I checked some passages whose transcription was
uncertain and prepared a free English translation. The transcript
was then coded in UK (following a scheme developed in a pilot
study (described in Wilson and Zeitlyn 1995)). In the course of
the coding the English translation was revised so that the use of
pronouns and names was parallel to their use in the Mambila
original - although there are obvious problems in this such as a
gender neutral third person and some (rare) compound pronouns.
The coding process turned up some further problems which were
resolved during a further fieldtrip in May 1994. The result is a
transcript that is of unparalleled quality for its type. This is
not to say that it is not theory laden (Ochs 1979) and inevitably
it could be improved, in particular the absence of a visual
channel combined with the free passage of children (and adults)
in and out of the house makes it uncertain just who the
non-participating audience is at any one time. In addition there
are often the voices of children at play in the background. Most
of the time these have proved too indistinct to be able to
transcribe. Almost any recording one makes in SomiŽ will
have the voices of children playing somewhere in the background!
Results
The research has gone broadly according to
schedule although the timing of field research in Cameroon was
altered due to political disturbances in that country. However,
the administration are familiar with me and I have had no problem
obtaining the necessary research permits. The main delay has
occurred in the preparation of transcripts which proved even more
time consuming than originally estimated. Rather than produce
more low quality material it was decided to produce less material
of high quality, and this has now been done. The resulting
transcript is of extremely high quality, having been checked in
the field in three successive stages of transcription and
translation. It represents a unique source of data that will be
of great value to those studying African languages. Since the
demands of time in the field were greater than originally planned
the extra work on the dictionary and comparative study of kinship
terminologies has not been undertaken. A draft dictionary exists
but this needs further work before it is in a form suitable for
circulation. This will not occur within the duration of the
project. Although regrettable this was never one of the major
priorities of the original proposal. It was decided that it was
best to concentrate on the core research in order to be able to
complete that on time. The data is being shared with Dr Connell,
a linguist working on the Mambila language with ESRC funding.
In the initial stages of the project a comprehensive literature
search was undertaken. This covered several disciplines ranging
from psychology through anthropology to conversation analysis.
Following this a pilot project was undertaken to establish an
adequate coding protocol. At this stage of research four papers
were written by Dr Zeitlyn and Mr Andrew Wilson, the RA1B
employed as part of this project. Zeitlyn (1993) presents a
theoretical overview of the project. Wilson  (1995)
(1995) (1995) is a survey of literature research
techniques for social anthropologists.
(1995) is a survey of literature research
techniques for social anthropologists.  Wilson, & Zeitlyn
(1994) is a detailed discussion of the work of William Stiles and
his attempt to code spoken discourse. Despite some reservations
about Stiles' theoretical position we feel that his taxonomy has
practical utility, and have used it as part of our own coding
scheme. Zeitlyn and Wilson
Wilson, & Zeitlyn
(1994) is a detailed discussion of the work of William Stiles and
his attempt to code spoken discourse. Despite some reservations
about Stiles' theoretical position we feel that his taxonomy has
practical utility, and have used it as part of our own coding
scheme. Zeitlyn and Wilson  (forthcoming)
(forthcoming) (forthcoming) is a discussion of a
set of computational tools (CLAN) designed for the study of talk.
Originally developed for developmental psychologists we outline
how it can be used as an ethnographic tool. It provides us with
the means to analyse our own material.
(forthcoming) is a discussion of a
set of computational tools (CLAN) designed for the study of talk.
Originally developed for developmental psychologists we outline
how it can be used as an ethnographic tool. It provides us with
the means to analyse our own material.
Having developed the coding scheme and tested for inter-coder
agreement scores, we then applied it to two American
conversations, using data made available by American colleagues.
These conversations are about forty-five minutes in length and
were selected to compare with the Mambila data, all the
conversations occurring as food was prepared and then eaten. The
analysis of the first of the conversations, along with a
comprehensive discussion of the methodology of the project are
presented in Wilson, & Zeitlyn (1995). The scheme has now
been applied to a corpus consisting of a conversation in a
similar setting but spoken by a Mambila family. The results of
this analysis, and the comparison with the American data are
being computed at this moment.
Outputs
- Wilson, A.J. 1995. A field-guide to bibliographic research.
Journal of the Anthropological
- Society of Oxford 25(2),
179-83.
- Wilson, A. J., & Zeitlyn, D. 1994. Speech acts and
Stiles. Linguistics and Education
- 6(1), 91-98.
- Wilson, A.J. & D. Zeitlyn. 1995. The Distribution of
Person Referring Terms in Natural
- Conversation. Research on Language and Social
Interaction 28(1), 61-92.
- Zeitlyn, D. 1993. Reconstructing Kinship or the pragmatics
of kin talk. Man 28(2),
- 199-224.
- Zeitlyn, D., & Wilson, A. J. forthcoming 1995. The
Childes Project: an anthropological
- resource. CAM. The Cultural Anthropology Methods
Journal .
It is planned to present some of the results at major
international conferences over the next two years as the final
results are fully tested and completed. A world wide web site
(The Virtual Institute of Mambila Studies) is also planned. This
will be hosted at University of Kent, Canterbury, and will
contain reports (such as this) and bibliographic data as well as
links to digitised sound recordings that I have already made
available on WWW.
Some of the theoretical background to the project has been used
in briefings given to Nokia Mobile Phones, UK.
Impacts
This project has demonstrated by example that
systematic research using data from naturally occurring
conversations can yield results of central importance for the
development of anthropological theories of kinship, as well as
being relevant to those working in applied arenas such as
communication technology. It should be stressed that this was an
unexpected benefit from the research which would not have
occurred had it been constrained by local and applied foci from
the outset.
Future research priorities
It is hoped that funding will
be forthcoming for the further development and testing of the
methods that have been developed in this project. In particular
we would like to explore hard testing of the theory by coding
partially and fully anonymised transcripts - from which
information about speakers has been removed. If the intuitions of
native speakers lead them to segment a transcript correctly and
if our analysis can replicate this then a (very) hard test will
have been performed. We have so far not succeeded in raising the
funding for this.
Another way in which the project may be extended is to consider
analysing other languages to make the cross-cultural test more
exacting. An obvious case to consider would be Japanese which is
notorious for the scarcity of pronominal usages, and the
complexity of its system of honorifics.
General report on results obtained to date.
Coding and counting. The broad brush and the fine
grain.
Counting words may produce some interesting results
particularly if accompanied by other information about the
sociology of the speakers and the speech act in question. Take
mother-in-law avoidance as a case in point. What people notice
and orient to are some regularities in the styles of talk and
some of these regularities are fairly crude in kind. For
instance, different words are used, or NOT used, when talking to
or about, mothers-in-law. What we gloss as mother-in-law
avoidance is, inter alia, that a son or daughter-in-law will not
address their mother-in-law. If we take a transcript of a group
of kin chatting we should find no (or relatively few) instances
of a son or daughter-in-law addressing their mother-in-law. I
hope that is not problematic and controversial but rather that it
demonstrates how the method can be linked to some mainstream
social anthropological concerns.
By contrast to the scale of much anthropology I am taking a
fine grain approach. The systematic and detailed analysis of
naturally occurring conversation poses many problems in its own
right, both of how the analysis should proceed and how the
results relate to conventional anthropological theorising. By
examining in detail the way in which speakers use small words
such as names, pronouns and kin terms we are asking questions at
a level where informants perceptions are not very acute. Speakers
are concerned generally with the issue at stake rather than their
choice of words. This is no bad thing, particularly since we are
in no wise suggesting that inability to describe what is going on
means that speakers are not (at some level) aware of the patterns
in their speech. The ease with which one can give insult and the
inappropriateness of saying, for example, 'Professor old cock' in
the seminar room or (even worse) in the PhD viva clearly
demonstrates this. Recognition of the possibility of such
inappropriate speech implies that there are social norms of
proper usage widely disseminated among a community of speakers
which we as students of human society can legitimately study. The
patterns of usage that may emerge are indicative of underlying
social/cultural phenomena.
Coding the data
Arguments for Crudity. The Lowest common denominator.
The
manner or style of speech is affected by a variety of social
factors such as: the relative ages, sexes and intimacy of
conversationalists. We focus on one particular element of speech:
the choice of expression used to talk about people (we talk of
Person Referring Expressions: PREs for short). To the
straightforward counting of the frequency of linguistic items
(such as PREs) we add some simple social variables, relying on
the simplicity of the coding categories to warrant their
application. The simple assessments required by our coding scheme
are those of a lowest common denominator. This seems legitimate
as a first approximation, in order to begin the analysis of the
data. It is definitely not, and must be taken as being, in any
way exhaustive. That caveat aside it seems prima
facie plausible that, for example, parents are more
powerful than their young children. The simplicity of the coding
permits us to be confident that we have correctly assessed what
is going on and that comparability may thereby be achieved. That
we have achieved acceptable inter-coder reliability scores
attests to this.
One of the surprises in the results was the lack of statistically
significant differences which could be found between the
conversations. To some extent this is a product of our relatively
small sample size. Small numbers restricts the validity of the
tests making it hard to obtain statistically significant results.
However, the project sought to pioneer new research techniques
and therefore can be regarded as a precursor to further more
extended research on larger datasets in which small numbers will
not restrict the statistical analyses. For, on the face of it,
there should be a world of difference between North American
families sitting round a table after a day at work or school and
a Mambila family preparing beer and food in the run up to a major
ritual in rural Cameroon. By aiming at rigour we may have
isolated ourselves from common-sense. Surely we know there are
important differences between Mambila and North America. However,
I would rather use this as a check on our common-sense intuitions
which we should recognise as being dangerously unreliable (as was
noted in the case of code switching above). If we can demonstrate
that some of those intuitions are correct then that is
not a trivial result. One of the major lessons
of anthropology is that native speaker intuitions, even of the
educated English, cannot be elevated to universal propositions
about the human population! It is no small task to try and test
the sense of similarity and difference that underlies so much of
anthropology. Hence, I would claim it as a non-trivial result
that in our pilot study of north American English we were able to
demonstrate that parents use names for their children and receive
kin terms back. In other words not only is there a norm but it is
demonstrably practiced, unlike other norms we may care to think
of which are honoured as much in the breach (both the prohibition
of murder and Grice's maxims for conversation (Levinson 101/2?)
have been suggested as candidates for such norms).
Comparing across languages
If we want to be able to
effect some meaningful comparisons between languages and cultures
we need be able to allow for variation in the linguistic factors.
In particular, some languages have a greater frequency of
pronouns than others. In Japanese, for example, pronouns are
notoriously rare. (Note that this implies that when they do occur
they are likely to be marked and hence of interest to
sociologists). What we have attempted to do is to normalise the
figures we use in order to take account of such factors.
If we sum over all speakers and conversations (within one
language) we get figures for the relative frequency of names,
kinterms and pronouns.
We can use those figures to normalise the frequencies of
individual speakers. A speaker may use many names relative to the
norm, or far fewer. The variations from the language specific
averages may be socially conditioned by factors such as the
social role of the speaker. The averages themselves reveal more
of the effect of the grammar of the language in question.
Mambila (one conversation)
PRO KIN NAME DES COMBINATIONS Total
1166 35 222 83 55 1561
Normalized
0.747 0.022 0.142 0.053 0.035 1
English (summing over two conversations)
PRO KIN NAME (TITLE and NAME) DES COMBINATIONS Total
1377 84 192 116 43 1812
Normalized
0.760 0.046 0.106 0.064 0.024 1
The data considered
The English language data analyzed
here consists of two conversations each made by a nuclear family
with a visitor in the setting of an evening meal. The dinner-time
setting determines the speech event under study, with its
specific scene, participants, and rules of interaction (see
Blum-Kulka, 1990). The speakers are white, middle-class,
Jewish-Americans with a guest/visitor, all from the east coast of
the U.S.. The Mambila data is the transcript of a conversation in
the house of one of my principal informants, his wife and some of
their children, with two adult visitors at different parts of the
conversation. The recording was made, in my absence and comments
made during the conversation show that those present were not
unaware of the presence of the tape recorder. Neither I nor
Mambila people who have heard the tape can ascertain any
significant difference between this conversation and others which
were not recorded. I have explained above how the transcript was
prepared. I am in the process of writing up what may be called
the 'thick ethnography' of this conversation in the form of an
annotated translation and a set of ethnographic diversions to
explain the significance of particular topics which occur in the
conversation, such as a description of a set of marriage gifts.
Two statistical results:
I shall now briefly present two
different statistical results.
1) A significant difference: explicit vocative use
One
statistically significant difference between the US English and
the Mambila data is found in the distribution of explicit
vocatives. We class as vocatives all PREs that
refer to the addressee, including pronouns kin terms, titles, and
names. When the distinction is made between pronouns and other
PREs, such as kin terms, names and titles, we call this latter
class 'explicit PREs' because they uniquely specify the addressee
in the vast majority of cases, whereas the denotation of a
pronoun is inherently contextual. Hence 'explicit vocatives' are
all vocatives excepting pronouns.
Distribution of Explicit Vocatives
We examined both the frequency of use of vocatives
and the social role of the person referred to. This led us to
construct a standardised measure of net vocative use, that is, a
measure of the extent to which a participant gives or receives
more vocatives. This figure is the number of vocatives used by
someone minus the number of times that person has been
uniquely1 referred to
with a vocative. Both are normalised to be the frequency per one
thousand utterances. In this respect, it seems from ¤1
that there is a clear difference between the cultures considered.
¤1:
It appears from this that Mambila parents use more explicit
vocatives than their American counterparts. Unfortunately I
suspect that this is a product of the data. There are far more
children speaking in the Mambila transcript and so the problem of
specification becomes more acute - sending a child or a younger
sibling out to fetch water is straightforward when there is only
one such person, more complex when there are several possible
candidates.
When we examined the total number of explicit vocatives used or
received by a speaker, their vocative involvement as it were, we
found it to be strongly correlated with involvement in what Brown
and Levinson call 'face-threatening acts' (FTA) (that is, ftas
given and received). See ¤2.
¤2:

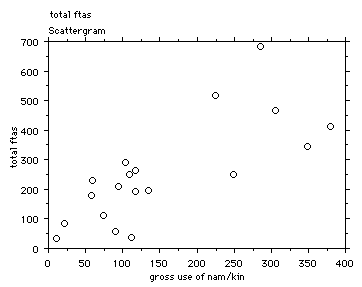
The likely explanation is that if there is an underlying factor
that has a role in determining the number of times one addresses,
and is addressed with, an explicit vocative, then this factor is
also responsible for the number of ftas one is involved with.
Later we will return to this suggestion in the discussion of the
factor analysis.
We next considered the role of social relationships in explicit
vocative usage. Having established that there are differences
between the Mambila and English data, we then considered if there
were any differences regarding social relationship. To do this we
examined the speaker-addressee pairs and the relationships
between them. Results may be seen in ¤3:
¤3
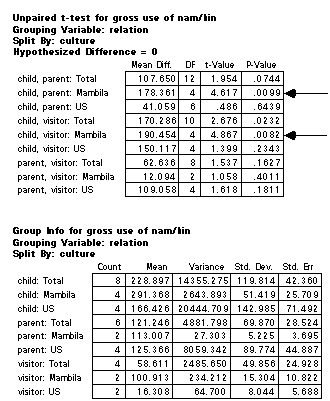
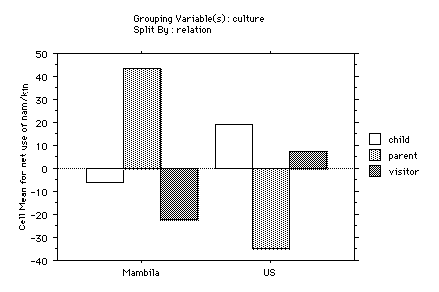
We can see from the figure and the table that in the Mambila
sample there is a significant difference between the categories
of child and parent. Mambila children and parents have
significantly different patterns of gross explicit vocative
involvement. In other words, Mambila parents produce and receive
more explicit vocatives than their children. The American sample,
however, shows no significant differences, although the visitor
is involved in fewer vocatives.
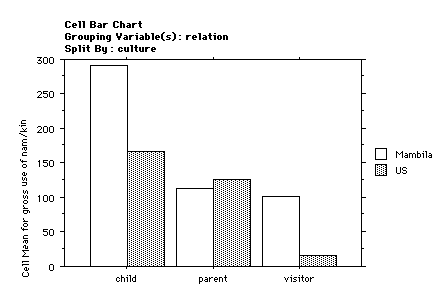
Let us examine this more closely by asking whether particular
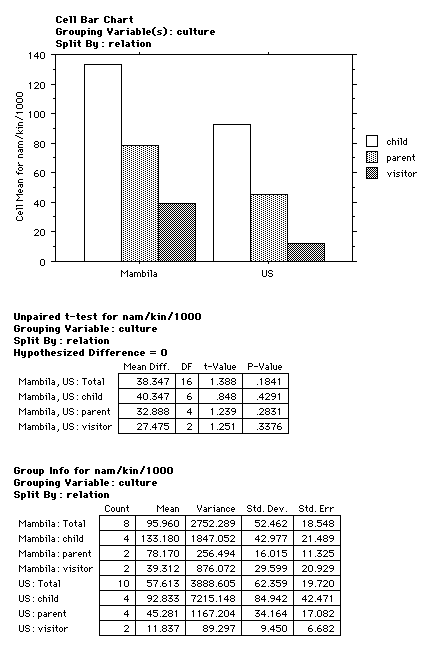
categories use or receive more or fewer kin terms and names?
¤4 shows the difference between the frequency of vocatives
uttered for each social category in the two cultures. It appears
that children utter more frequently than parents, who, in turn,
utter more frequently than visitors. This is true in both
cultures, though it appears that Mambila enjoys a higher overall
frequency. The cultural differences are not significant, but
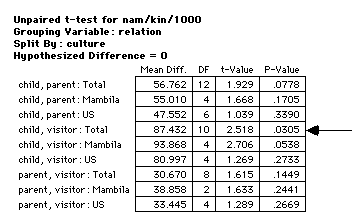
there is a significance between children and visitor as shown in
¤5.
¤4:
¤5:
Looking at the production of explicit vocatives we can see
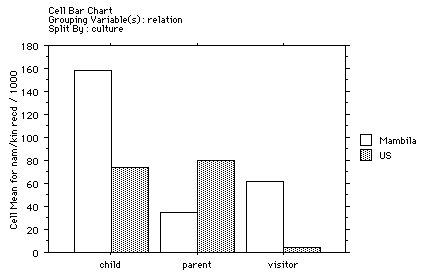
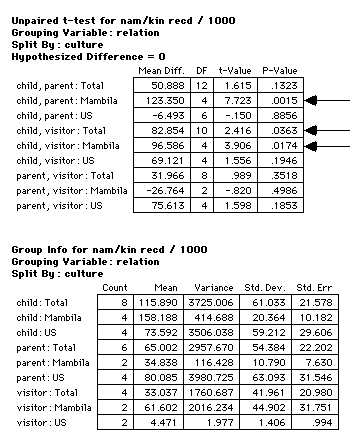
(¤5) that children are more prone to using vocatives than
their parents, in both Mambila and American cultures. However, in
Mambila there is a significant difference between parent and
child receiving explicit vocatives, whilst there is no such
difference between parent and child in the American samples.
¤6
{{Page X}}
2) Introducing a factor analysis
The second statistical
analysis that will be discussed here took all the data together,
pooling the English and Mambila results suitably normalised,
looking for factors to account for some of the variation within
the conversations.
As an initial step, we further simplified the data by considering
only the utterances that had unique addressees. Since there are
many possible permutations of conversational dyads we then
restricted ourselves to the more frequently occurring dyads,
choosing to ignore dyadic pairs that occurred less than ten times
(which as we have already noted may itself be a significant list
- It does not need Sherlock Holmes to point to the mother-in-law
who is not addressed...)
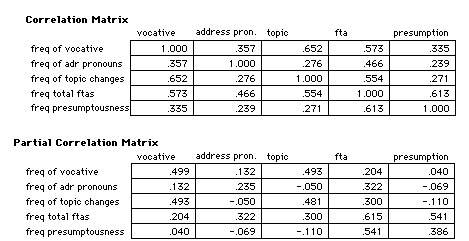
We considered five variables within in the utterances:
1) Use of explicit vocatives
2) Address Pronoun
3) Involvement in (either giving or receiving ) FTAs.
4) Topic Change
5) SSA - measure of 'Presumptuous' Intent
The last variable uses the work of William Stiles to provide a
means to investigate the link between PRE use and Brown and
Levinson's analysis of politeness phenomena. The intent of each
utterance is to coded according to three principles (source of
experience, presumption about the experiences of others, and the
frame of reference). These create eight possible categories that
represent different types of speaker-addressee
micro-relationship. One of Stiles' guiding assumptions is that
each category carries with it an associated set of grammatical
features. This enables the linguistic form of the utterance to be
coded separately according to grammatical rules with the same
eight categories. Thus a declarative sentence in the first person
('I' or 'we' that does not include the hearer) may be coded as a
'Disclosure' form, whereas a sentence whose subject is first
person plural ('we') and includes the hearer is to be coded as a
'Confirmation' form. In this way, an utterance may share the same
code for intent and form or have different codes, as in the
following examples (Stiles 1992, p. 10):
(1) 'Sit down' (pure Advisement).
(2) 'Would you like to sit down?' (Question form with
Advisement intent).
(3) 'I'd like you to sit down' (Disclosure form with Advisement
intent).
From the preceding, it is clear that by
reformulating one's intent in a grammatical form that is
typically reserved for other types of intent one is performing a
strategy akin to facework (see Goffman as elaborated by Brown and
Levinson). Indeed, Stiles identified (1981) 'presumptuousness' as
a connection between his classification scheme and the model of
politeness strategies of P. Brown and Levinson. The four intent
categories that are considered 'presumptuousness' may be said to
be intrinsically face-threatening: 'Advisements' are those
utterances that threaten negative face, and 'Confirmations',
'Interpretations' and 'Reflections' threaten positive face. The
intrinsic threat can be dissipated by using a non presumptuous
linguistic form such as examples (2) and (3).
Having selected these five variables an initial statistical
analysis was performed. In this we asked to what extent the
distributions of these different variables can be seen as
resulting from fewer underlying factors. If such factors are
identifiable there is the possibility of interpreting them as
being basic principles that are instrumental in the choices
people make of the PREs they use.
Having conducted the factor analysis for the variables above we
then continued to explore how the factors we have identified may
relate to other, more sociological variables. To do this we
calculated the values of the factors for each dyad and then
sought to relate this to the coding of each dyad for the social
distance between the speaker and addressee (intimate, distant),
and the gradient of status difference (i.e. whether they are
talking 'up', 'down' or 'sideways').

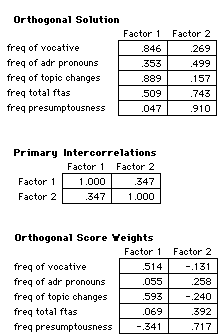
Two factors emerged, onto which the five variables loaded
quite well (a variable loads with a value of +-0.3 onto one
factor and hardly at all onto the other). Pronouns/1000, total
ftas/1000, presumptuousness load onto factor 2, whilst
vocatives/1000 and topic changing / 1000 load onto factor 1. In
order to see where each dyad falls relative to the others we
returned to the data and calculated standardised scores for each
of the factors. This requires calculating the difference of each
dyad compared to the mean of the sample, all divided by the
standard deviation of the sample. Thus giving a standard
variation of mean zero, and standard deviation one. We then used
graphs of the dyads to investigate the role of status and
intimacy in the variables used for the factor analysis.
Plotting the dyads against the two factors but marking them for
the gradient of status, in other words, whether the addressee is
of greater, equal or lower social status than the speaker,
produces the following graph:
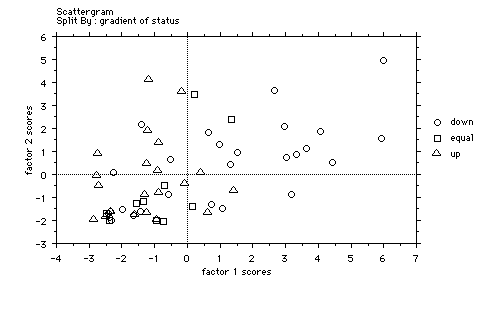 Note
how the dyads where the speaker was of lower status than the
addressee (i.e. child to parent) are to the left, and those where
the speaker was of higher status than the addressee (i.e. parent
to child) to the right. In other words, factor 1 appears to
discriminate between the relative social status of the
conversants. The clustering of eight dyads in the same place
shows the limits of the analysis.
Note
how the dyads where the speaker was of lower status than the
addressee (i.e. child to parent) are to the left, and those where
the speaker was of higher status than the addressee (i.e. parent
to child) to the right. In other words, factor 1 appears to
discriminate between the relative social status of the
conversants. The clustering of eight dyads in the same place
shows the limits of the analysis.
In the next graph we relate a simple measure of intimacy to the
factors already identified.
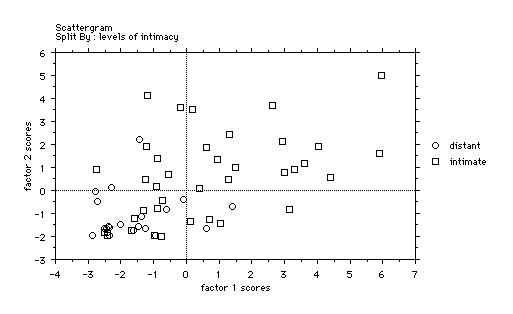 This shows
the problems that face us in seeking to interpret the factors we
have identified. At first sight factor 2 seems independent from
intimacy since the dyads are evenly distributed over the whole
range of factor 2, but closer inspection shows a slight tendency
of the distant dyads to have low factor 2 values (i.e. to occur
on the bottom half of the graph), yet the intimate dyads occur
for all values of factor 2. Factor 1 shows a slight articulation
with intimacy, a higher value of factor 1 seems connected to
greater intimacy but it is far from clear.
This shows
the problems that face us in seeking to interpret the factors we
have identified. At first sight factor 2 seems independent from
intimacy since the dyads are evenly distributed over the whole
range of factor 2, but closer inspection shows a slight tendency
of the distant dyads to have low factor 2 values (i.e. to occur
on the bottom half of the graph), yet the intimate dyads occur
for all values of factor 2. Factor 1 shows a slight articulation
with intimacy, a higher value of factor 1 seems connected to
greater intimacy but it is far from clear.
To help interpret these results consider first the results of
extending this factor analysis by including positive and negative
politeness in our list of variables. The factors then increase to
three. In the table that follows I have omitted the factor scores
when they are less than 0.3 to aid clarity.


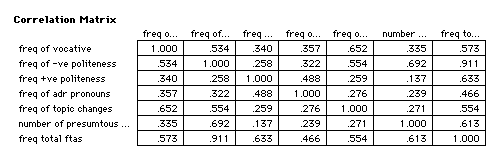 What is
revealing about this is the way that the third factor seems
mainly implicated in topic change and use of explicit vocative.
Note also the spreading of total FTA involvement over all three
factors. Brown and Levinson could take heart from this for one
factor that they identify which we have been unable to take into
account is the ranking of imposition. Asking for a glass of water
is different for asking for a thousand pounds.
What is
revealing about this is the way that the third factor seems
mainly implicated in topic change and use of explicit vocative.
Note also the spreading of total FTA involvement over all three
factors. Brown and Levinson could take heart from this for one
factor that they identify which we have been unable to take into
account is the ranking of imposition. Asking for a glass of water
is different for asking for a thousand pounds.
Consider again the smaller analysis.

Now the classic models to account for choice of terms are first
those proposed in Brown and Gilman's 'The pronouns of power and
solidarity' which we may gloss as 'status' and 'intimacy'. This
approach was generalised by Brown and Levinson who identified
three factors (status, intimacy and ranking of imposition) as
determining the choice of politeness strategy to be employed,
choice of term being a critical such strategy. The factors that
these theories deploy relate interestingly to Mary Douglas's grid
and group or even Durkheim's integration - regulation
distinction.
We are then posed the challenge of attempting the interpretation
of the factors identified by the statistical analysis. How can
these factors be linked to the sort of solid, sociologically
revealing variables that conventional analysis deploys? In short
my question is whether Brown and Gilman should take heart from an
interpretation of factor 1 as status and factor 2 as intimacy (or
vice versa)? I think that what these results show is that such a
simplistic reading is not possible - we have shown that there are
more things in heaven and earth than are dreamed of in Brown and
Gilman's (or even Brown and Levinson's) philosophy! Among these
are semantics, at least in the form of the importance of topic
shift. This may itself be related to power, and hence to social
status. For one manifestation of power in a conversation is the
control over the topic of conversation and how it shifts. Very
stark examples of this may be found in television and radio
interviews, but it has also been analyzed in the context of
family conversation by Richard Watts (1991). To a dimension
involving semantics we appear to require a further one that
inter-relates status and intimacy. This sort of complexity may be
the appropriate way to further expand Brown and Levinson's model
to try and take account of some of the recent criticisms that
have been levelled at it.
This is a starting point for further research. For the present I
conclude with the claim that, counter Brown and Gilman and Brown
and Levinson, status and intimacy cannot be satisfactorily
separated in the analysis of naturally occurring
conversation.
Bibliography
- Blum-Kulka, Shoshana 1990. 'You don't touch lettuce with
your fingers: parental
- politeness in family discourse.', Journal of
pragmatics , Vol. 14, pp. 259-288.
- Brown, P.B., and S.C. Levinson 1978. 'Universals in
Language Use: Politeness Phenomena',
- in E.N. Goody (ed.) Questions and Politeness ,
Cambridge: Cambridge University Press, pp. 56-290.
- Brown, R, and A Gilman 1960. 'The pronouns of power and
solidarity', in T.A. Sebeok
- (ed.) Style in Language , Cambridge, Mass: MIT
Press, pp. 253-76.
- Ochs, E. 1979. 'Transcription as theory', in E. Ochs and B.
Schieffelin (eds.) Developmental
- pragmatics , New York: Academic.
- Stiles, W.B. 1981. 'Classification of intersubjective
illocutionary acts.', Language
- in Society , Vol. 10, pp. 227-249.
- Stiles, William B. 1992. Describing Talk: a Taxonomy
of Verbal Response Modes (Interpersonal
- Communication 12), Newbury Park: Sage.
- Watts, Richard J 1991. Power in family discourse.
Contributions to the sociology
- of language 63 , Berlin: Mouton de
Gruyter.
Part C Publications for inclusion in RAPID
- copy of
electronic submission already received by RAPID
award number R000 23 3311
Article in Journal
%A Andrew J. Wilson
%D 1995
%T A Field-Guide to Bibliographic Research
%J Journal of the Anthropological Society of Oxford
%V25
%N 2
%P 179-83
Refereed? No
award number R000 23 3311
Article in Journal
%A Andrew J. Wilson
%A David Zeitlyn
%D 1994
%T Speech acts and Stiles
%J Linguistics and Education
%V 6
%N 1
%P 91-98
Refereed? Don't know
award number R000 23 3311
Article in Journal
%A Andrew J. Wilson
%A David Zeitlyn
%D 1995
%T The Distribution of Person Referring Terms in Natural
Conversation
%J Research on Language and Social Interaction
%V 28
%N 1
%P 61-92
Refereed? Yes
award number R000 23 3311
Article in Journal
%A David Zeitlyn
%D 1993
%T Reconstructing Kinship or the pragmatics of kin talk
%J Man
%V 28
%N 2
%P 199-224
Refereed? Yes
award number R000 23 3311
Article in Journal
%A David Zeitlyn
%A Andrew J. Wilson
%D forthcoming 1995
%T The Childes Project: an anthropological resource
%J CAM. The Cultural Anthropology Methods Journal
Refereed? No
award number R000 23 3311
Dataset
Mambila transcript
archived in the CHILDES (Child Language Data Exchange System)
database.
FTP poppy.psy.cmu.edu (128.2.248.42).
The files are in /childes/noneng
mambila.tar
mamfonts.sea.hqx
award number R000 23 3311
Dataset
Mambila transcript
Submitted to ESRC Data Archive July 1995
award number R000 23 3311
Consultancy
David Zeitlyn
Consultancy to Nokia Mobile Phones UK
Sociolinguistic aspects of communication: mediated and direct
throughout 1995